Apr 22, 2021
The Beginning of Infinite Data: How to generate infinite synthetic training data for computer vision
Written by Lina A. Colucci, Sidney Primas, & Andrew Weitz at Edge Analytics
It’s no secret that big companies make use of user data to train their machine learning models. Google and Facebook have a billion new images per day uploaded to their servers. The cute cat image you uploaded to Instagram was probably used to train Facebook’s latest vision model. And now Google is asking you to label your photos to make their job of developing models on your data even easier.
Startups and individual researchers cannot get access to the same scale of data as larger companies, but synthetic data is changing that. Synthetic data includes any data — images, videos, time series, and more — that is generated entirely via simulation, as opposed to being measured directly with a sensor in the real world. Using a simulator means that researchers have explicit control over their dataset, can generate infinite¹ training samples, and do not need to go through the laborious process of labeling each sample. Synthetic data is poised to democratize access to larger datasets and empower anyone to solve machine learning problems at the scale of big tech companies.
At Edge Analytics, we are constantly developing solutions to collect the best datasets we can — after all, an ML model is only as good as the data it is trained on. When we found that existing pose estimation models, which track key points of the human body, were not accurate enough for our applications, we decided to build an API to generate the relevant synthetic datasets.
Synthetic data led to real improvements in our model’s performance, plus turned out to be an invaluable ML developer tool in 3 surprising ways. Synthetic data allowed us to (1) debug faster, (2) characterize our (otherwise black-box) deep learning models, and (3) tailor the reach² of our models.
We are excited about synthetic data and empowering people to solve real-world problems without being constrained by lack of data.
If you are interested in gaining access to our Synthetic Data API, please sign up here or get in touch at info@edgeanalytics.io.
Synthetic data is poised to democratize access to larger datasets and empower anyone to solve machine learning problems at the scale of big tech companies.

Synthetic data works (and it works well!)
We trained pose estimation models on a mixture of real-world COCO images and synthetic data from our API, targeting poses that fall outside the domain of traditional datasets like COCO. On these activities, our pose estimation models outperform state-of-the-art models!

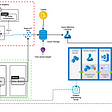
What We Built: An API for Infinite Data
We built an API that allows users to generate an arbitrary number of synthetic images to solve pose estimation problems. The API generates data according to parameters in a YAML file, which include distributions of camera positions, avatars (clothing, body shape, age, skintone, etc.), movement trajectories, lighting conditions, and more. We use a command line interface to generate as many simulated scenes as we want based on those parameter combinations.
Our API also generates perfectly accurate labels and other metadata for no additional effort since the entire scene is programmed. Currently, the API’s labels are the 2D positions of the avatar’s joints (including occluded joints).The simulator can also provide ground-truth labels that are difficult or impossible to get from human annotators, such as 3D keypoint positions, depth, velocity, and more.
We feed the synthetic images and labels through a Python augmentation pipeline that is designed to work in synchrony with our simulator. For example, we (1) perform clothing and/or body-part occlusion augmentation based on metadata from the synthetic images, and (2) replace the simulation’s green screen background with Google Street View snapshots.
For access to our Synthetic Data API, please fill out this form.

What We Learned: 3 Surprising Benefits of Synthetic Data
We expected synthetic images to be useful as training data, but were surprised at how useful synthetic data was beyond that as well.
Synthetic Data Enabled Us to Debug Faster
Running into model failure modes is an inevitable part of machine learning, but simulated data has allowed us to debug failure modes faster. As one example, we ran into a failure mode where our pose estimation model was not transferring to new subjects. We hypothesized that we needed more variation in avatar appearances in our training dataset. We used the Synthetic Data API to test this hypothesis and generate training data that varied the number of distinct characters and the appearance of their clothing. We ultimately found that we needed the right balance between the two variables — both increasing the number of characters and occluding their clothing — to achieve the best model performance. Simulated data allowed us to debug our model faster because we had all the necessary data at the click of a button.

Synthetic Data Enabled Us to Characterize Our Models
Deep learning models can often be black boxes, but simulated data has allowed us to better characterize the models we build. We use the Synthetic Data API to both:
- Build a library of edge cases that we include as part of our validation set, and
- Precisely characterize the performance of our model across a specific variable.
For example, using the Synthetic Data API we generated synthetic images with varying lighting conditions and were able to plot our model’s performance as a function of lighting. Or, in another experiment, we characterized model performance as a function of camera position. Synthetic data has given us a convenient sandbox for running controlled experiments and quantitatively understanding the models we build.
Synthetic Data Enabled Us to Tailor the Reach of Our Models¹
When we productize ML models, we need to tailor the model to its target domain. Simulated data gives us control over the type and amount of variation in our training datasets. Rather than requiring lengthy real-world data collection cycles, we can generate training data tailored to the reach of our specific problem at the click of a button. For example, both automated grocery stores (like Amazon Go) and interactive dance games (like Wii or Kinect dance games) need pose estimation models but for very different target domains. An automated grocery store needs to work on video from a ceiling view, whereas a dance game played on your living room TV needs to work on data from that home environment. Both products need to accurately track human poses from video but they need to be optimized for different input data. Our Synthetic Data API allows us to generate training data tailored to our specific problem.

Conclusion
People like to say that data is the new oil. Certainly data is indispensable in this era of deep learning, and access to large, well-labeled training data is often restricted to only the biggest companies. Synthetic data will not only democratize access to data, but also allow engineers to make progress faster by providing a sandbox in which to experiment and address failure cases. Synthetic data is not a silver bullet to all of computer vision’s challenges, but it is no doubt an important part of computer vision’s future.
Sign up for the API
If you are interested in gaining beta access to our Synthetic Data API for Pose Estimation, please fill out this form or get in touch at info@edgeanalytics.io! We would love to hear from you.
¹ Near infinite is more accurate. Of course neither compute nor storage are infinite, so neither is synthetic data. But our API can generate an arbitrary number of synthetic images whose theoretical limit is, in fact, infinite.
² Credit to The Beginning of Infinity by David Deutsch for helping to crystallize the concept of “reach.” We are fans of the book, as you might have been able to guess by the title of this blog (“The Beginning of Infinite Data”).
This synthetic data work was a team effort by the entire Edge Analytics team! A major thank you to Edge team members Andrew Weitz, Caleb Kruse, Ken Jung, Sidney Primas, and Vasiliy Nerozin for all their incredible work in building these models and tools. Thank you to Diana Kimball Berlin plus Edge team members Brinnae Bent and Ren Gibbons for reading early versions of the blog and providing feedback.

Edge Analytics is a company that specializes in data science, machine learning, and algorithm development both on the edge and in the cloud. We provide end-to-end support throughout a product’s lifecycle, from quick exploratory prototypes to production-level AI/ML algorithms. We partner with our clients, who range from Fortune 500 companies to innovative startups, to turn their ideas into reality. Have a hard problem in mind? Get in touch at info@edgeanalytics.io.