Dec 15
EXPEDIA GROUP TECHNOLOGY — DATA
How to Optimise Rankings with Cascade Bandits
Using contextual bandits will help surface attractive items you could have otherwise missed
Getting started
If you have never addressed a ranking problem before, it can seem a bit overwhelming. You might even be asking yourself, “Where can I start?” If you find yourself in this position, this blog will show you how we optimised the ranking of components on a home page by using cascade bandits.
Learning-to-rank algorithms trained on user interactions with supervised learning approaches are widely and successfully used: from lodging ranking personalisation to flight ranking. However, these models may reach suboptimal solutions due to the noisy nature of the implicit signals inferred from user interactions. Bandit algorithms are commonly used to address this issue by exploring new solutions while balancing the need to maintain a good user experience.
In this blog, we’ll go over what a ranking problem is, what cascade bandits are and how we used them to solve our ranking problem. By the end of this blog, you’ll have a better understanding of how to address ranking problems using cascade bandits.
Learning to rank
In general, learning to rank is the process of teaching a computer how to sort items based on some specific criteria (usually relevance). We have a candidate set of items D and we want to find the best ranking of a certain length K, less than or equal to the number of candidates. In the example, in Fig 1 we have 4 candidates and we are interested in finding the best ranking of length 2. We can build 12 of such rankings as you can see.

Ranking problems are important because they are at the heart of modern interactive systems, such as recommender and search systems. Models are learned directly from users’ interaction feedback in order to better understand and predict how they will rank different items. In this way, we can present to each user more personalised and relevant results.
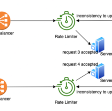
Users’ interaction feedback is usually gathered as described in Fig 2. The ranker generates a list that is served to users. They interact with the content, for example clicking on an item, then click data flows into the ranking system. The click data is used by the ranking system to improve itself.

Bandit feedback
From a machine learning perspective, the ability to learn the best ranking properly is more challenging than we may think. This is due to the fact that users’ interaction feedback is not full-information feedback.
In order to understand why this occurs, let’s consider a simplified scenario: a machine learning algorithm recommends 1 item from a set of 3. In a full-information scenario, feedback would look like what is shown in Figure 3. The algorithm chooses to recommend the backpack and receives feedback on all items, even those that were not shown. Users indicate that they preferred the museum over the other two options. This is an example of supervised learning, where the model chooses a class for a given instance to be classified and the target variable is the correct class.

However, this is not the kind of feedback we get. Let’s see why it is different in two steps. Firstly, the algorithm doesn’t receive any feedback on items it didn’t recommend (see Fig 4). In this scenario, it still knows for sure that the backpack is not what users wanted because they refused it explicitly. However, we know this is still not realistic.

In a real use case feedback on the backpack is implicit, like a click in Fig 5. The fact that the backpack is clicked doesn’t necessarily mean that this is what users would have wanted to receive as a recommendation. It could indicate that users would be interested but another item might be better. As a matter of fact, we know the museum is the best option from the previous examples. This implicit signal that is inferred from user interactions is noisy.

If we train a supervised learning algorithm using clicks as the target variable, the algorithm will learn the backpack is the best option and it will keep recommending it. In this way, it will miss out on the museum, which would have generated the optimal click-through rate. The optimal candidate is ignored simply because it is never exposed to users.
The only way to break this pattern is exploration: we need a strategy to pick candidates not yet tried out (or not tried enough) instead of always exploiting (pick candidates that seem best based on past outcomes). Any selection strategy risks wasting time on “duds” while exploring and also risks missing untapped “gems” while exploiting. Bandit algorithms are designed to balance exploration and exploitation in the most optimal manner and can solve this problem.
What we said about a single-item recommendation is true for ranking problems as well. In this case, the available options, the arms in the bandit lingo, are rankings. We can use bandit algorithms (as we described in a previous post) to find the best ranking, balancing exploration and exploitation.
Structured bandits
However ranking problems pose another challenge. Since a ranking is a permutation of candidate items, the number of possible rankings can be huge. If we have 15 items and we want to find the best ranking of length 10 then we have roughly 11 billion arms. Gathering enough feedback for each arm could be impractical. How can we address this problem?
Let’s go back to the 12 rankings example we introduced previously. An algorithm is trying to understand which arm is the best and selects the first one. Then users click on the first item so the arm receives a reward of 1 (Fig 6).

If we look at the arms we can clearly see they aren’t really independent. Other arms contain the beach umbrella or the backpack. We can try to exploit structures in the rankings and focus on the items (that we call sub-arms) rather than the rankings themselves. The reward of an arm is the sum of the rewards of its sub-arms, so 1 is assigned to the beach umbrella and 0 to the backpack. This kind of feedback provides insight into other rankings without choosing them (Fig 7). This is an example of what we call a structured bandit problem [1].
Once we learn which are the best sub-arms, we can use them to build the best ranking.

Cascade model
A learning-to-rank algorithm should also address the position bias, which is the phenomenon that higher-ranked items are more likely to be observed than lower-ranked items. A common approach to address it is to make assumptions about the user’s click behaviour and model the behaviour using a click model [2].
The cascade model is a simple but effective click model to explain user behaviour. It makes the so-called cascade assumption, which assumes that users browse the list from the first-ranked item to the last one. They click on the first attractive item and then stop browsing. The clicked item is considered to be positive, items before the click are treated as negative and items after the click will be ignored (Fig 8). The cascade assumption can explain the position bias effectively and many algorithms have been proposed under this hypothesis.

In the cascade model, the probability that the user clicks on an item at position k can be factorised in two terms (Fig 9). The first term is the attractiveness function, which measures the probability that the user is attracted to item a. This probability doesn’t depend on the position of the item in the ranking. The second term can be interpreted as the probability that the user examines that item.

The probability of examination, under the cascade assumption, is the probability that the user has not clicked on the first k − 1 items (Fig 10).

The model is parametrised only by the attraction probabilities. Once we have them, we can calculate both examination probabilities and click probabilities (Fig 11). If we learn those probabilities, we can sort the items accordingly and build the ranking.

Cascade Linear Thompson Sampling
A key assumption, which allows us to learn efficiently, is that we assume that the attraction probability of each item can be approximated by a linear combination of some known d-dimensional feature vector z that represents the sub-arm (possibly along with other contextual features) and an unknown d-dimensional parameter vector β star:
The exploration-exploitation trade-off can be handled using Thompson sampling [3], which consists of choosing the arm that maximises the expected reward with respect to a randomly drawn belief. A popular algorithm that implements such a strategy is the CascadeLinTS algorithm [4] (another option is LinTS-Cascade(λ) described in [5]).
CascadeLinTS algorithm operates in 3 stages (Fig 12):
- it randomly samples a parameter vector from a normal distribution, which approximates its posterior on β star. Then it estimates the expected attraction probabilities using the linear model.
- the algorithm chooses the optimal ranking with respect to its estimates.
- it receives feedback and updates its prior distribution which will become more peaked around the most promising parameter values.
Finally, after a certain number of interactions the probability distribution will be so concentrated that exploration will stop.

Fig 13 shows the results of a simulation we run using RL-saloon, our in-house developed framework for simulations and off-policy evaluation. RL-saloon allows us to test algorithms under different environment setups. In this particular simulation, we have 10 candidates and we want to find the optimal ranking of length 5 depending on the context. We represent items as one-hot-encoded features in the z vector. Contextual features are formed by two categorical variables with three levels and one continuous variable. The click simulator in the environment follows the cascade assumption.
In Fig 13 we show the regret incurred by CascadeLinTS (Bandit) and the cascade linear model without exploration (Greedy) after 100k interactions. The regret measures the loss suffered by the learner relative to the optimal solution. As we can see, the greedy algorithm incurs a larger regret compared to cascade bandits because it fails to gather enough information to find the best ranking.

Conclusion
In this blog post, we introduced ranking problems and described how we solve them at Expedia Group using cascade bandits (n.b. property ranking on Expedia search result page is powered by a different specialised algorithm). In the future, we intend to incorporate other click models, like the Position-Based Model, and to address how to balance relevance and diversity.
References
[1] Tor Lattimore and Csaba Szepesvári. Bandit Algorithms. Cambridge University Press, 2020.
[2] Aleksandr Chuklin, Ilya Markov, and Maarten de Rijke. Click Models for Web Search. Synthesis Lectures on Information Concepts, Retrieval, and Services. Morgan & Claypool Publishers, 2015.
[3] Daniel Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. A tutorial on thompson sampling. Foundations and Trends in Machine Learning, 11(1):1–96, 2018.
[4] Shi Zong, Hao Ni, Kenny Sung, Nan Rosemary Ke, Zheng Wen, and Branislav Kveton. Cascading bandits for large-scale recommendation problems. In Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence, UAI 2016, New York City, NY, USA. AUAI Press, 2016.
[5] Zixin Zhong, Wang Chi Chueng, and Vincent Y. F. Tan. Thompson Sampling Algorithms for Cascading Bandits. Journal of Machine Learning Research, 22:218:1–218:66, 2021.